关于软件测试课程
SJTU-SE3336-软件测试 课程笔记
1. 软件测试概述
1.1. 概念
软件测试的核心是设计测试用例来识别代码中的错误。
测试的目的:发现软件中的错误。
高效的软件测试的核心:通过最小的测试代价(如最少的测试用例),系统地达到测试目的。
一个好的测试是能以更高的概率找到未找到的错误。
流程:设计测试计划 -> 生成测试用例 -> 搭建测试环境 -> 执行测试用例 -> 验证测试结果 -> 判断测试覆盖率(test coverage)是否达到指标 -> 决定是否继续测试
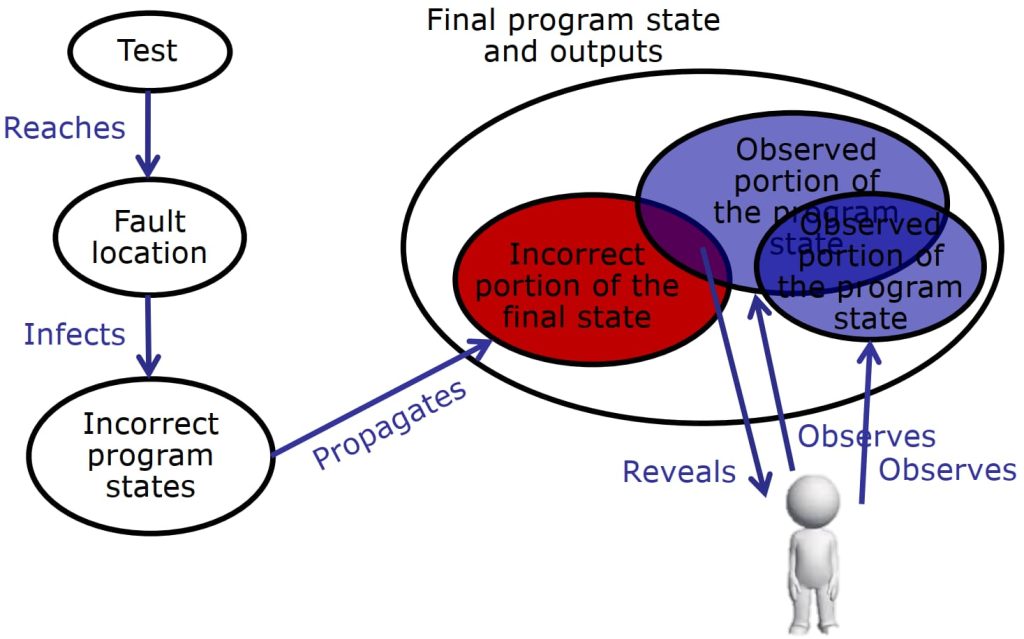
1.2. RIPR Model
- Reachability(可达性):错误可以被测试用例所到达
- Infection(传染):错误的执行会导致程序不正常的状态
- Propagation(传播):错误引起的程序状态的改变会传播,是最终的输出或者状态不正常
- Revealabity(可揭示性):测试需要能观察到程序状态不正常的部分
1.3. Myers principle
- 早期测试与持续测试
- 避免由程序员本人测试其编写的软件
- 测试用例(Test Case):
- 测试用例 = 输入数据 + 预期结果。
- 测试用例应包括预期的(有效的)输入数据和非预期的(无效的)输入数据。
- 测试程序(Test Program)包括程序应该做的内容和不应该做的内容。
- 存在错误的概率与已发现错误的数量成正比。
- 全面检查每次测试的结果。
1.4. 测试层次
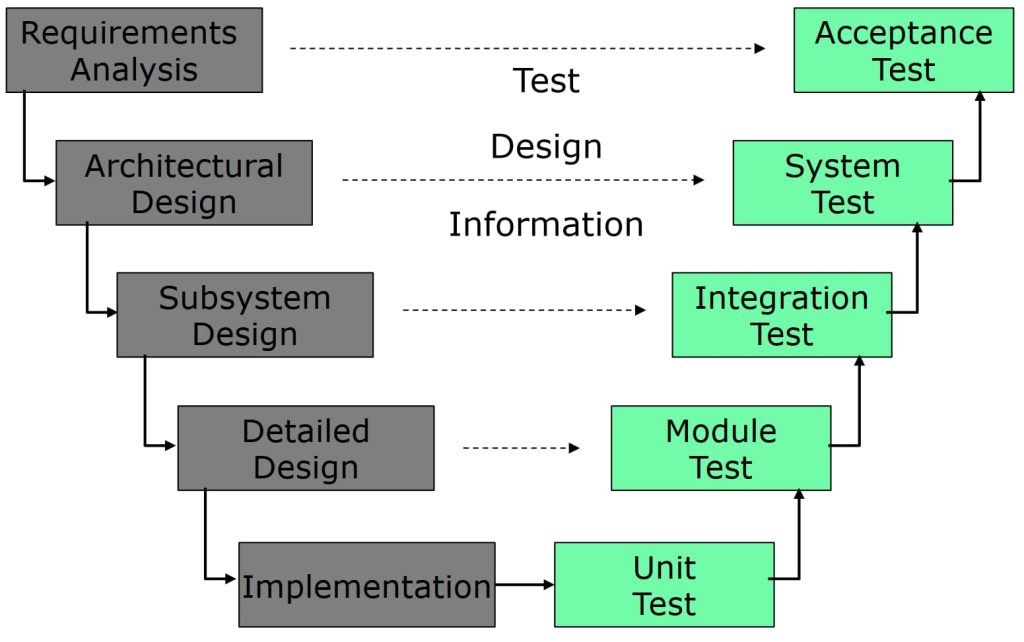
传统瀑布模型的观点:
- 单元测试:面向详细设计,完成对软件独立模块的测试
- 集成测试:面向概要设计,完成软件模块之间的组合测试
- 系统测试:面向需求分析(需求规格说明),完成系统的功能测试
2. 基础理论和方法
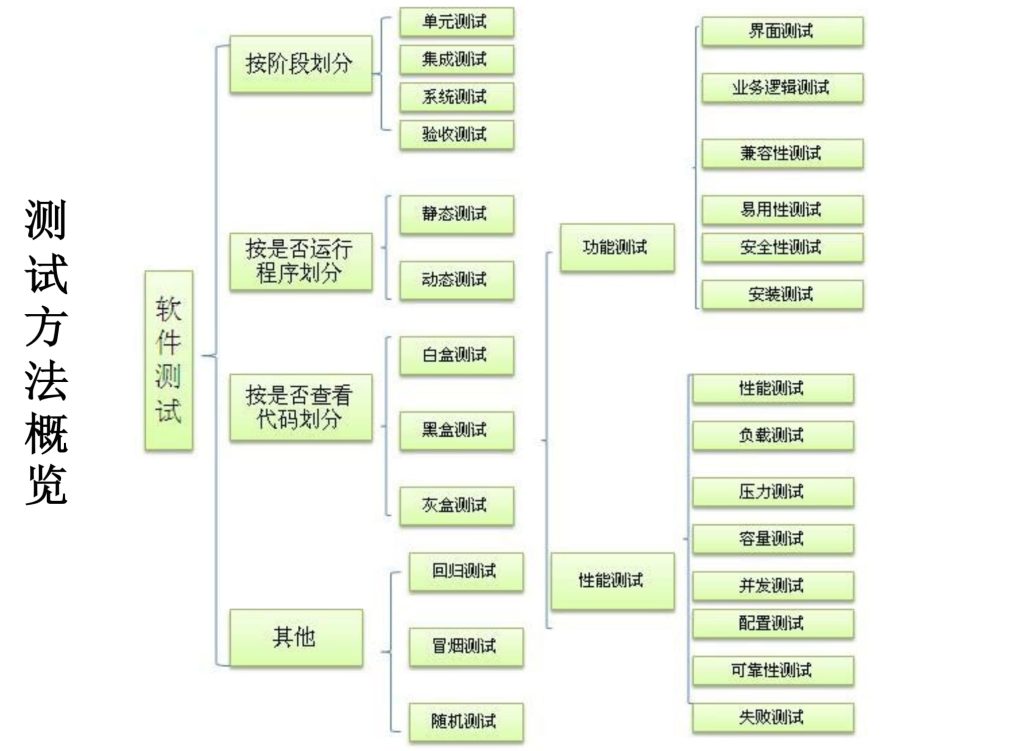
2.1. 测试方法概览
2.2. 静态测试(Non-execution based Verification)
2.2.1. Walk through(代码走查)
无需执行程序,利用工具审查和分析规格说明及程序代码。
- 流程步骤
- 组建走查测试小组
- 检查程序代码逻辑
- 生成测试用例(含输入数据与预期结果)
- 运行数据验证:若计算结果不符预期,则发现错误
- 逐行审查代码
- 核心目标
- 发现缺陷,而非修正缺陷
- 执行方式
- 由主导人带领团队逐步审查代码
- 可基于问题清单或代码本身驱动讨论
- 成员适时提出疑问,即时讨论并归类:
- 需修复的缺陷
- 通过讨论澄清的疑点
2.2.2. Inspection(代码审查)
- 流程步骤
- 概述(Overview):作者向团队讲解模块设计。
- 准备(Preparation):参与者详细阅读代码,按严重性分级列出问题(参考潜在缺陷检查表)。
- 审查(Inspection):逐行走查代码,确保全覆盖;主持人24小时内提交书面报告。
- 返工(Rework):负责人修复报告中的所有问题(记录于 Individual Reviewer Issues Spreadsheet)。
- 跟进(Follow-up):主持人验证问题是否解决(通过代码修正或澄清),更新 Review Report Spreadsheet。
- 核心目标
- 通过严格流程系统性降低缺陷,提升代码质量。
- 关键产出
- 缺陷统计:按严重性分类记录的数量与类型。
- 质量评估:
- 若某模块缺陷数显著高于其他模块,建议重写。
- 若多个模块存在同类错误,需扩展检查其他模块。
- 5%规则:若返工内容超5%,需全员重新审查。
2.3. 动态测试(Execution based Verification)
- 核心方法:
- 通过测试用例执行程序,获取运行结果并验证是否符合预期。
- 目标:
- 通过动态执行暴露程序错误,确保软件行为符合设计与需求。
- 两大测试策略
测试类型 名称 核心思想 基于规格测试 黑盒测试(Black-box) 仅关注输入输出,不查看内部逻辑 基于代码测试 白盒(White-box) 针对代码结构设计用例(如分支、路径覆盖)
2.3.1. 黑盒测试
- 核心思想:仅关注输入输出是否符合规格说明,不查看内部代码逻辑。
- 部分测试方法:
- 等价类划分:将输入数据划分为若干等价类,每个类选取代表值测试(减少用例数量)。
- 边界值分析:重点测试输入范围的边界值(如最小值、最大值、略超出边界的值)。
- 功能测试:针对模块的每个功能点设计测试用例。
- 局限性:
- 无法覆盖所有可能的输入组合(尤其大规模系统)。
- 可能遗漏代码内部的异常分支或未实现的需求。
- 示例:
- 输入范围
(a, b),测试:- 正常值(
a < x < b) - 边界值(
x = a,x = b) - 异常值(
x < a,x > b) - 五个等价类(
x < a,x = a,a < x < b,x = b,x > b)
- 正常值(
- 输入范围
2.3.2. 白盒测试
- 核心思想:基于代码内部逻辑设计测试用例,覆盖程序结构(如分支、路径)。逻辑/路径驱动的结构化测试,测试深层次的结构性错误。
- 部分测试方法(覆盖率用来证明测试是充分的):
- 语句覆盖:确保每条语句至少执行一次。
- 分支覆盖:覆盖所有条件分支(如
if-else、switch)。 - 路径覆盖:覆盖所有可能的执行路径(复杂代码中难以完全实现)。
- 局限性:
- 路径组合爆炸问题(复杂模块难以全覆盖)。
- 可能遗漏与代码逻辑无关的需求错误(如未实现的隐性需求)。
2.4. 形式化验证(Formal verification)
属于数学方法,通过形式化逻辑(如霍尔逻辑 / Hoare Logic)严格证明程序行为符合规格说明。
2.5. 其他方法
- 定义使用测试(Def-use test)
- 回归测试(Regression test)
- 变异测试(Mutation test)
- 故障统计与可靠性分析(Fault Statistics and Reliability Analysis)
- 净室方法(Clean Room)
3. 功能性测试(Functionnal Test)/ 黑盒测试
核心概念:根据程序外部特征进行测试。
测试依据(原则):软件开发过程对应的需求规格说明书。
强要求:测试后能定位到错误位置。
3.1. 边界值测试
3.1.1. 基本边界值测试
- 边界值测试的取值:最小值 min,略高于最小值 min+,正常值 norm,略低于最大值 max-,最大值 max
。 - 基于单缺陷假设:
- 失效极少是由2个(或更多)缺陷同时发生引起的。
- 即选取测试用例时仅仅使得一个变量取极值,其他变量均取正常值。
- 对分析错误定位位置友好。
- N个变量的测试用例数:4N+1。
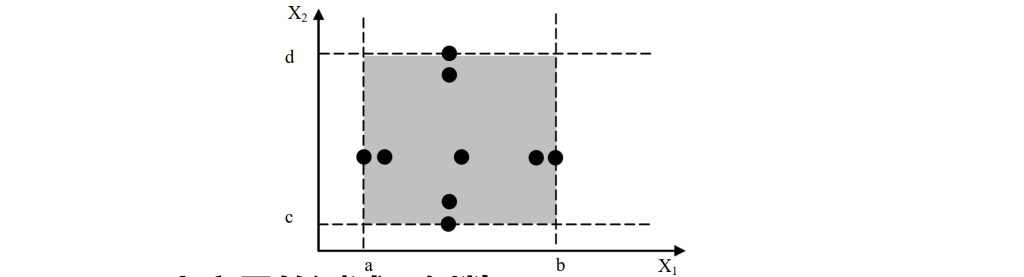
3.1.2. 健壮性测试
- 要考虑无效值输入:略小于最小值 min-,最小值 min,略高于最小值 min+,正常值 norm,略低于最大值 max-,最大值 max,略大于最大值 max+。
- 基于单缺陷假设。
- N个变量的测试用例数:6N+1。
3.1.3. 最坏情况测试
- 拒绝单缺陷假设,考虑全部边界输入的组合,即各个变量输入的笛卡儿积(多缺陷)。
- 基于多缺陷假设:
- 失效是由两个或两个以上缺陷同时作用引起的,要求在选取测试用例时同时让多个变量取极值。
- 最坏情况测试:N 个变量的测试用例:5N(未考虑无效输入)。
- 健壮(增加2个无效输入)最坏情况测试: N 个变量的测试用例: 7N
3.1.4. 随机测试
- 使用随机函数取出测试值,避免了人为的测试偏见。
- 停止阈值:保证每类输出至少有一个
3.2. 等价类测试
测试核心:划分:互不相交的一组子集,这些子集的并是全集。
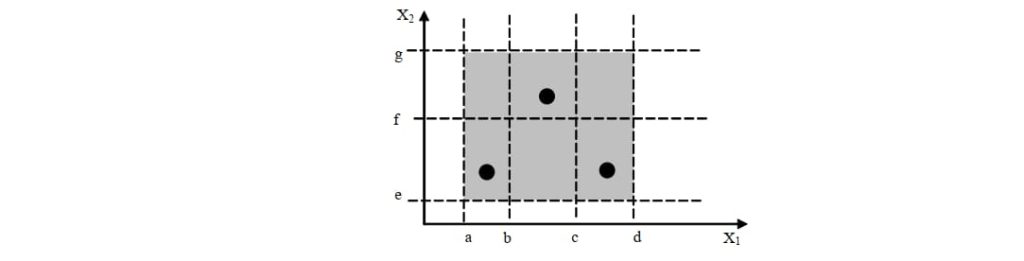
3.2.1. 弱(单缺陷)一般等价类
- 覆盖单缺陷
- 测试数:取 N、M 中的大者
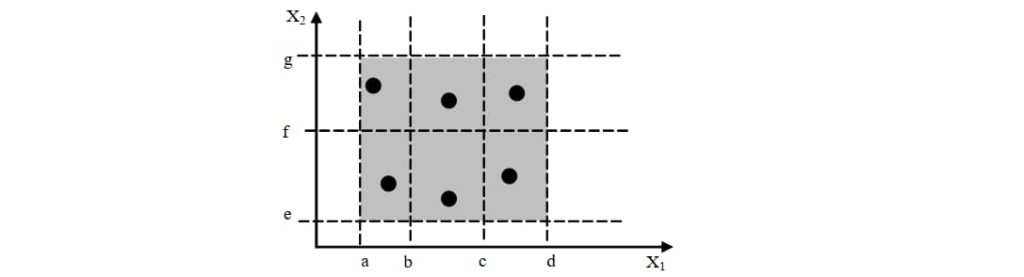
3.2.2. 强(多缺陷)一般等价类
- 覆盖多缺陷,考虑不同划分的笛卡尔积
- 测试数:N × M
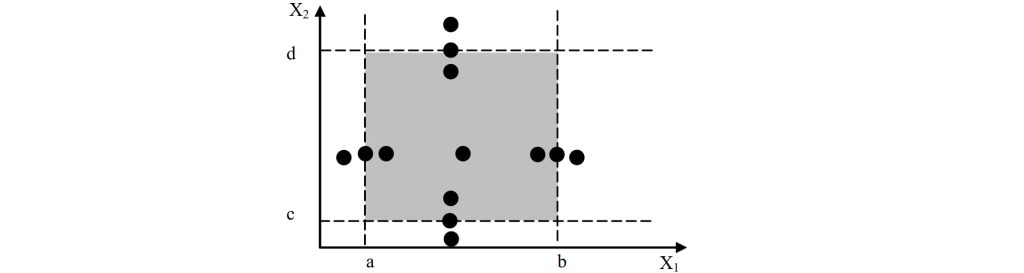
3.2.3. 弱(单缺陷)健壮等价类
- 覆盖单缺陷
- 健壮:考虑无效值
- 测试数:取 N、M 的大者(3)再加无效值(2)
- 错误定位不便利
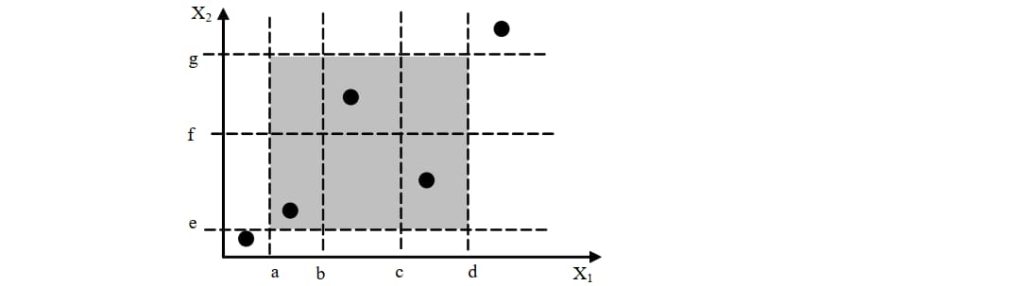
- 测试数:取 N、M 的大者(3)再加无效值(2X变量个数)
- 错误定位便利
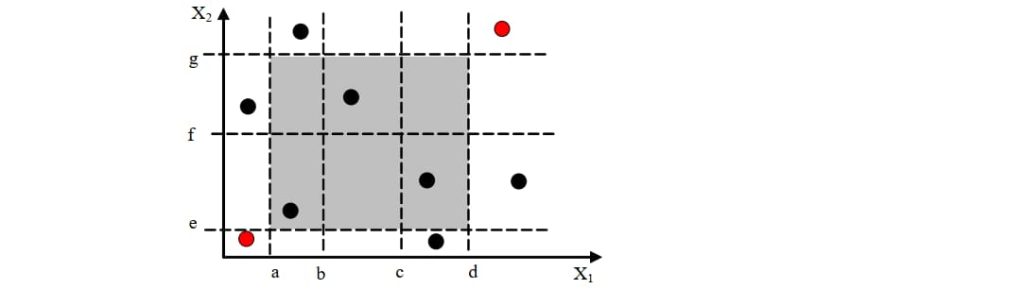
3.2.4. 强(多缺陷)健壮等价类
- 覆盖多缺陷
- 健壮:考虑无效值
- 测试数:(N+2)×(M+2)
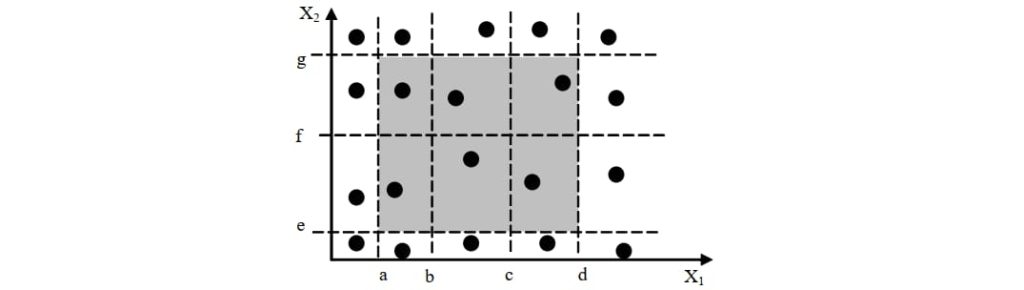
3.3. 基于决策表的测试
决策表能够将复杂的问题按照各种可能的情况全部列举出来,以避免测试需求的遗漏。
决策表由四部分组成(桩 + 条目)×(条件 + 行动):
- 条件桩:列出了测试对象的所有条件。一般情况下,列出的条件的次序不会影响测试对象的动作。
- 动作桩:列出了测试对象所有可能执行的操作。一般情况下,这些执行的操作没有先后顺序的约束。
- 条件项:列出针对特定条件的取值,即条件的真假值。
- 动作项:列出在不同条件项的各种取值组合。
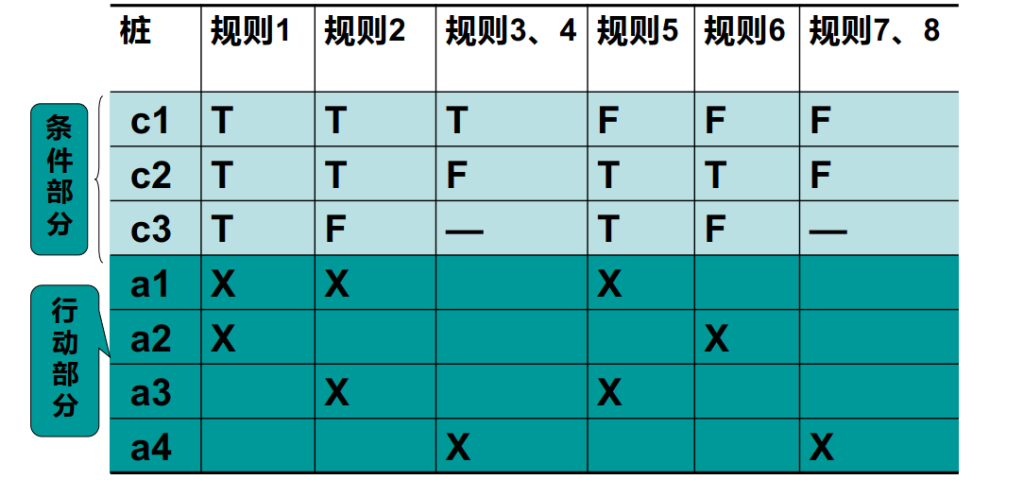
决策表测试步骤:
- 列出所有的条件桩和动作桩
- 填入条件项
- 填入动作项,制定初始判定表
- 简化、合并相似规则或者相同动作
3.3.1. Nextdate 函数 示例
第一次尝试,等价类如下:
| M1 | M2 | M3 | D1 | D2 | D3 | D4 | Y1 | Y2 |
| 月:30天 | 月:31天 | 月:2月 | 日:1~28 | 日:29 | 日:30 | 日:31 | 年:闰年 | 年:平年 |
共有 28 = 256 条规则
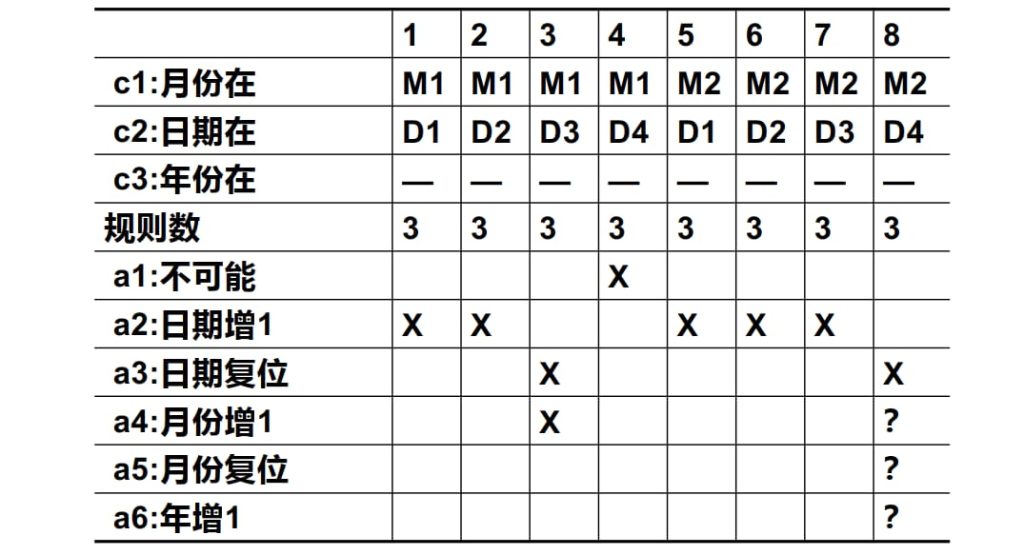
第二次尝试,注意力集中在闰年问题上:
| M1 | M2 | M3 | D1 | D2 | D3 | D4 | Y1 | Y2 | Y3 |
| 月:30天 | 月:31天 | 月:2月 | 日:1~28 | 日:29 | 日:30 | 日:31 | 年:闰年且世纪年 | 年:闰年且非世纪年 | 年:平年 |
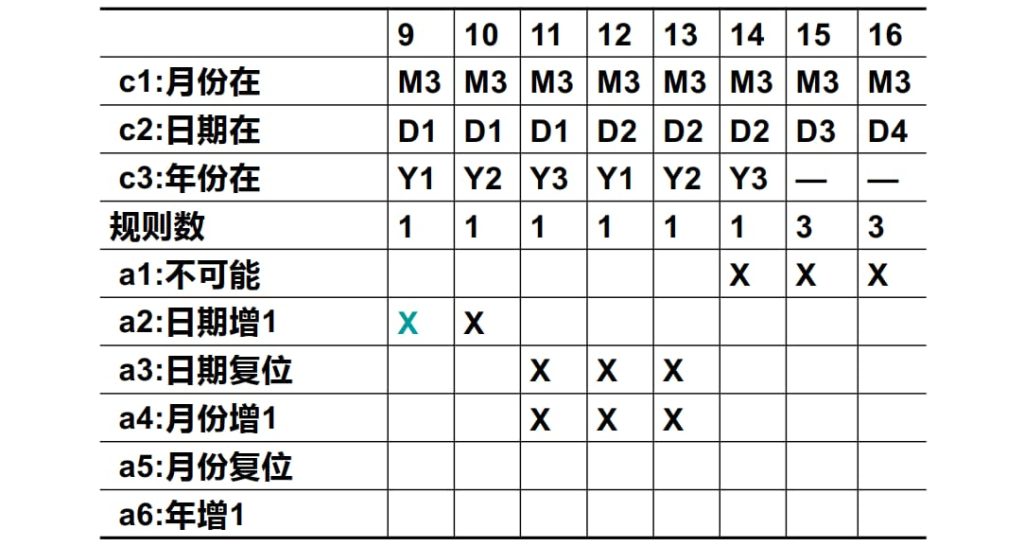
第三次尝试,对2月的27进行特别划分:
| M1 | M2 | M3 | M4 | D1 | D2 | D3 | D4 | D5 | Y1 | Y2 |
| 月:30天 | 月:31天,12月除外 | 月:12月 | 月:2月 | 日:1~27 | 日:28 | 日:29 | 日:30 | 日:31 | 年:闰年 | 年:平年 |
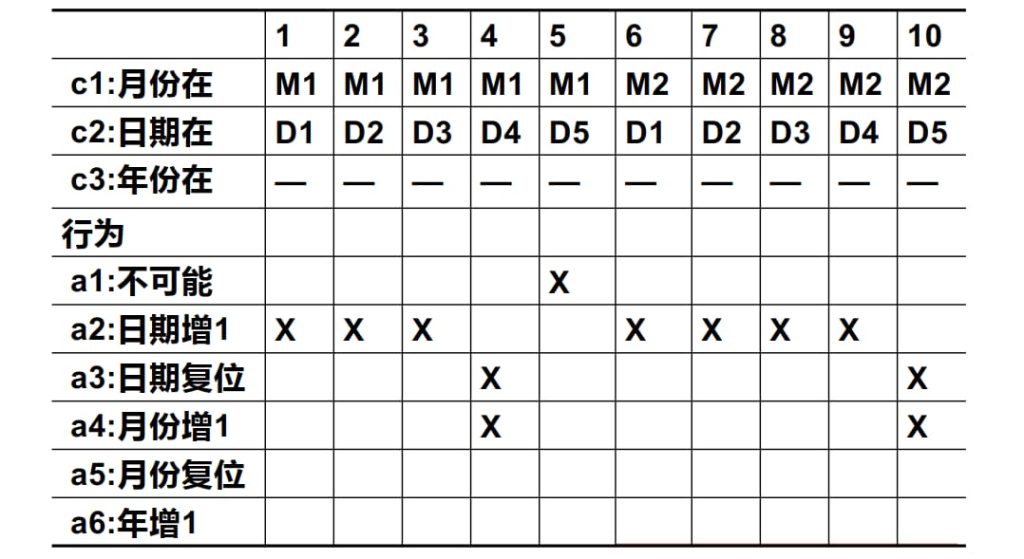
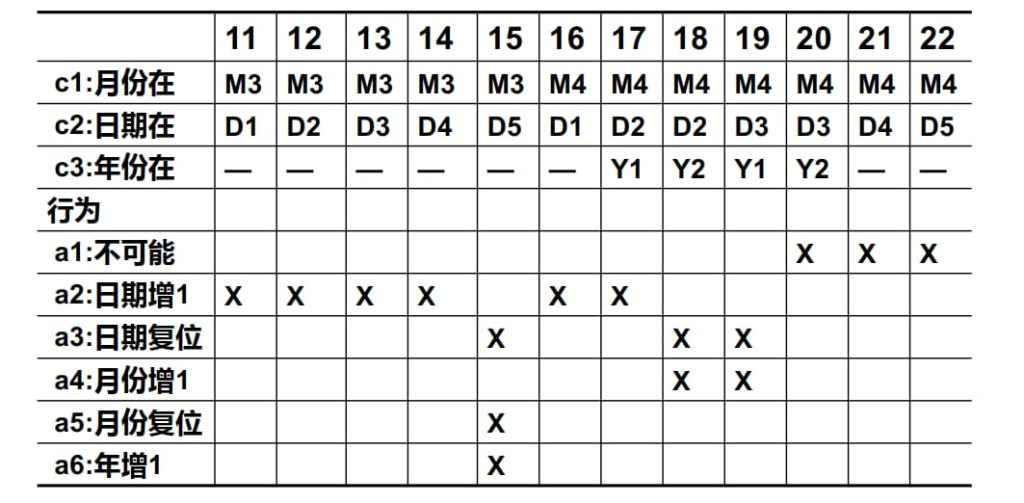
进一步,考虑等价类的合并:
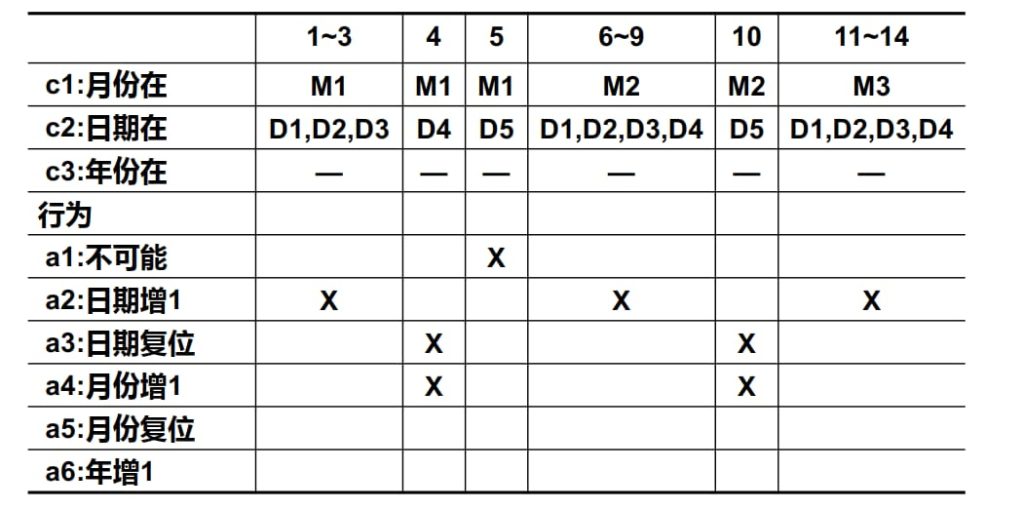
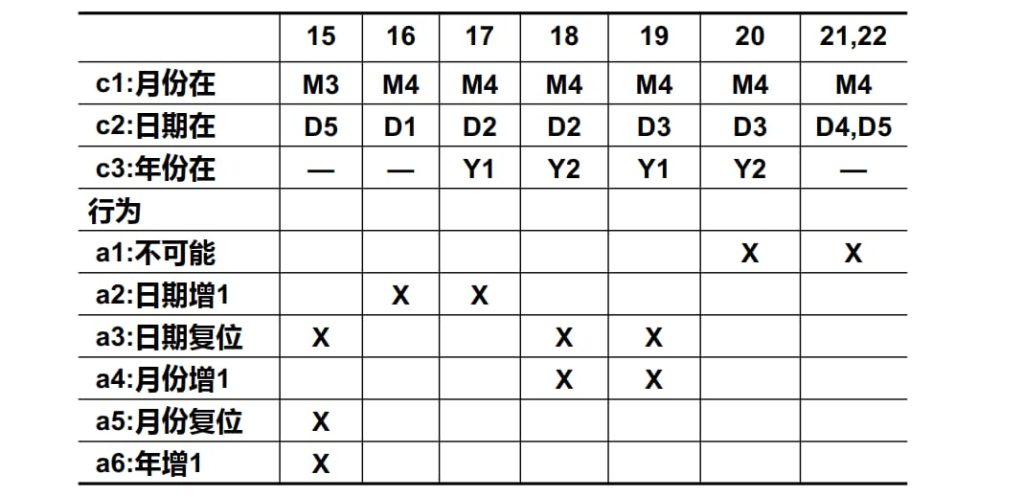
从第一次的256个测试规则到现在的13个测试规则,测试等价类的完备性是一样的。
换言之,从决策表测试方法,我们可以充分地认识到,测试用例越多,并不能增加测试的完备性。而通过分析与合并,使用尽可能少的测试用例来达到测试完备性要求,正是测试技术研究的核心内容和目标。
3.4. 测试的效率
软件测试技术研究的目标:使用尽可能少的测试用例,发现尽可能多的软件错误。提高测试的效率。
- 如果变量引用的是物理量,可采用边界值分析和等价类测试;
- 如果变量是独立的,可采用边界值分析和等价类测试;
- 如果变量不是独立的,可采用决策表测试;
- 如果可保证是单缺陷假设,可采用边界值分析和健壮性测试;
- 如果可保证是多缺陷假设,可采用最坏情况测试、健壮最坏情况测试和决策表测试;
- 如果程序包含大量例外处理,可采用健壮性测试和决策表测试;
- 如果变量引用的是逻辑量,可采用等价类测试和决策表测试。
4. 结构性测试(Structure Test)/ 白盒测试
核心概念:根据程序内部逻辑结构进行测试,力求提高测试覆盖率。
两大方法:
- 路径测试
- 数据流测试
4.1. 路径测试
核心目的是测试程序的结构。
4.1.1. 程序图
- 程序图是一种有向图,图中的节点表示语句片段,边表示控制流。
- 如果 i 和 j 是程序图中的节点,从节点 i 到节点 j 存在一条边,当且仅当对应节点 j 的语句片段可以在对应节点 i 的语句片段之后立即执行。

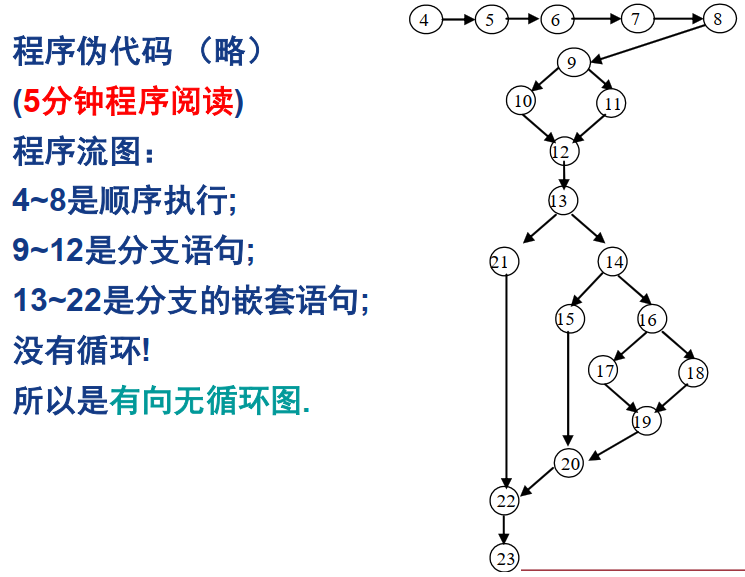
4.1.2. DD-路径图(决策到决策)
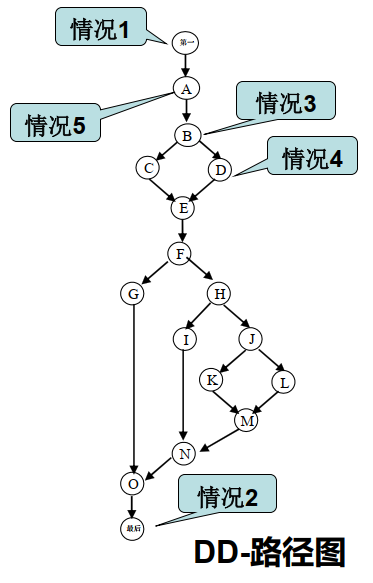
对于给定的程序,可以使用多种不同的程序流图,所有这些程序流图,都可以简化为唯一的DD-路径图; 换言之,DD-路径是程序图中的最小独立路径,不能被包括在其它DD-路径之中;换言之,DD-路径是一种压缩图,其中的一个节点(DD-路径),对应程序中的语句片段。
DD-路径是程序图中的一条链,使得:
- 情况1:由一个节点组成,入度=0。
- 情况2:由一个节点组成,出度=0。
- 情况3:由一个节点组成,入度 >= 2或出度 >= 2。
- 情况4:由一个节点组成,入度 = 1并且出度 = 1。
- 情况5:长度 >= 2的最大链(单入单出的最大序列)。
4.1.3. 测试覆盖指标
测试评测方法的核心在于覆盖和质量两个维度:
- 测试覆盖(Test Coverage)
- 本质:衡量测试完整性的量化指标
- 表现形式:
- 基于需求的覆盖:测试用例对需求规格的覆盖比例
- 基于代码的覆盖:已执行代码占代码总量的比例
- 测试质量(Test Quality)
| 指标 | 覆盖描述 |
| C0 | 所有语句(语句覆盖) |
| C1 | 所有DD-路径(分支覆盖) |
| C1p | 所有判断的每种分支(条件判断) |
| C2 | C1 覆盖+循环覆盖 |
| Cd | C1 覆盖+DD-路径的所有依赖对偶 |
| Cmcc | 多条件覆盖 |
| Cik | 包含最多 K 次循环的所有程序路径(通常K = 2) |
| Cstart | 路径具有“统计重要性”的部分 |
| C∞ | 所有可能的执行路径 |
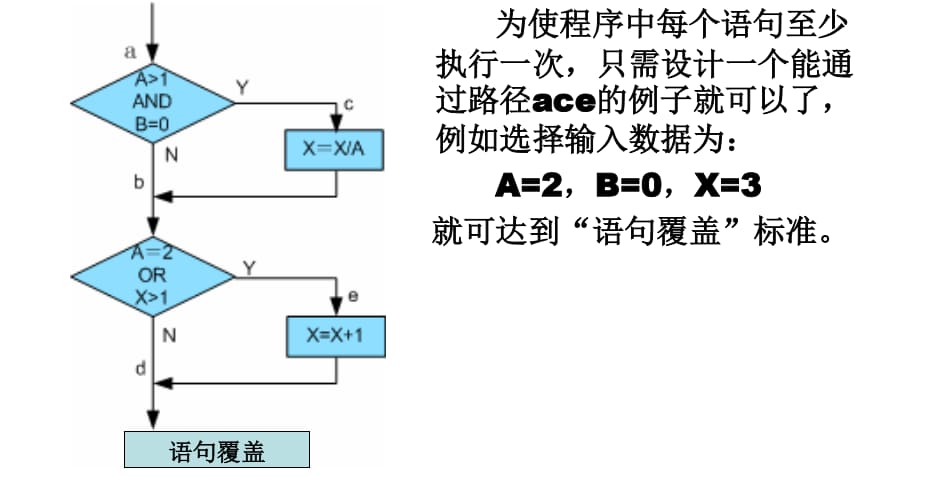
4.1.3.1. 语句覆盖(C0)
使程序中每一可执行语句至少执行一次;
4.1.3.2. 分支覆盖(C1)
确保每个逻辑判断(如 if、while、for 等)的 True 和 False 分支都被执行过。
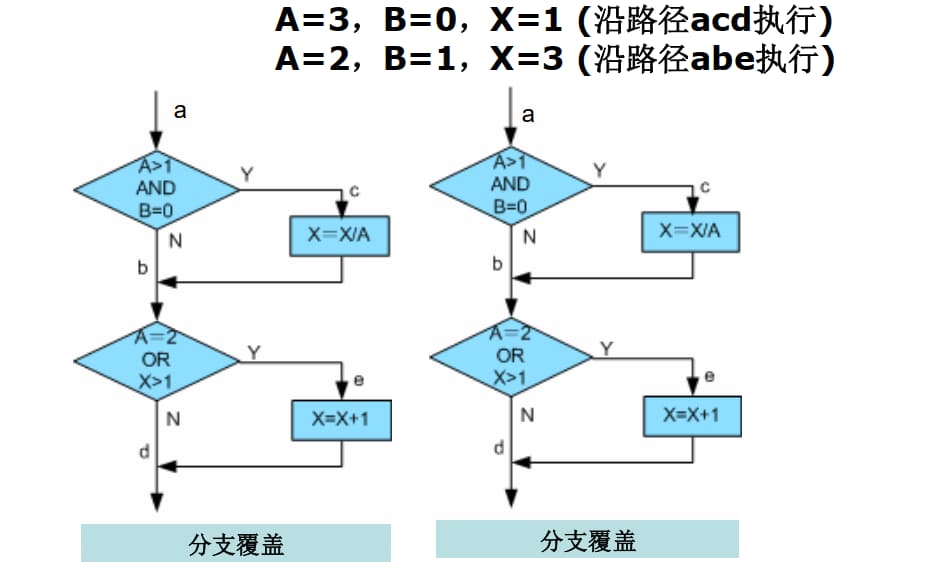
4.1.3.3. 条件覆盖(C1p)
确保每个子条件(原子条件)的 True 和 False 情况都被独立测试,而不管整个判断的分支走向。
条件覆盖满足与分支覆盖满足没有直接关系。

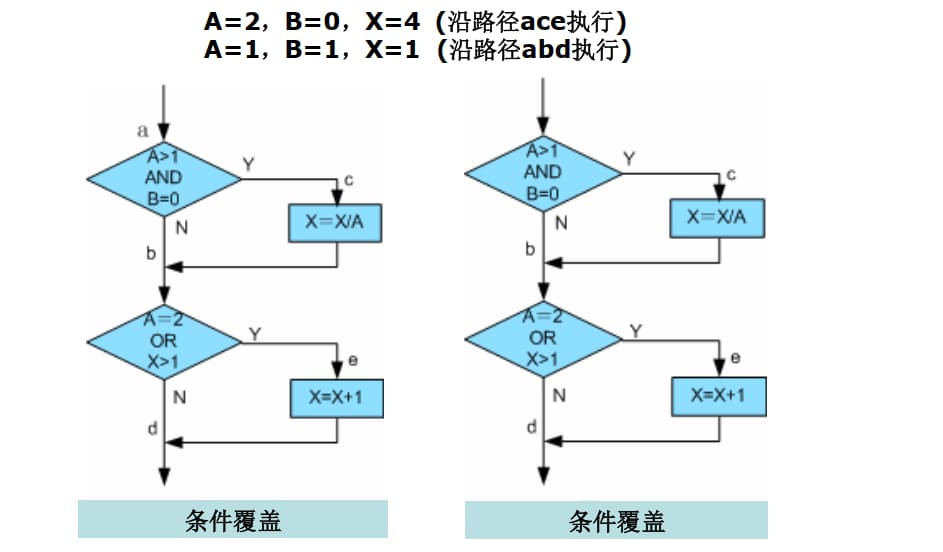
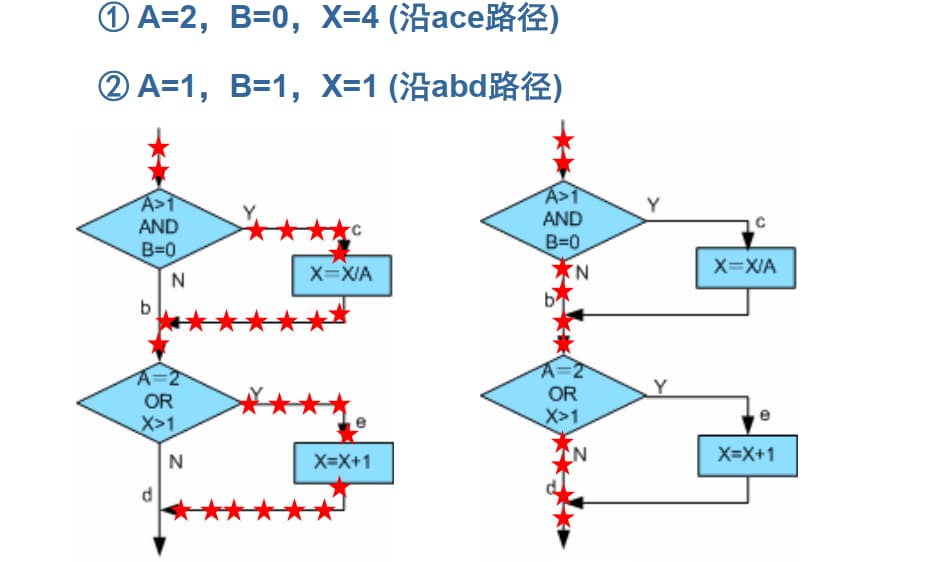
4.1.3.4. 多条件覆盖(Cmcc)
确保每个逻辑判断中子条件的各种可能组合都至少出现一次。

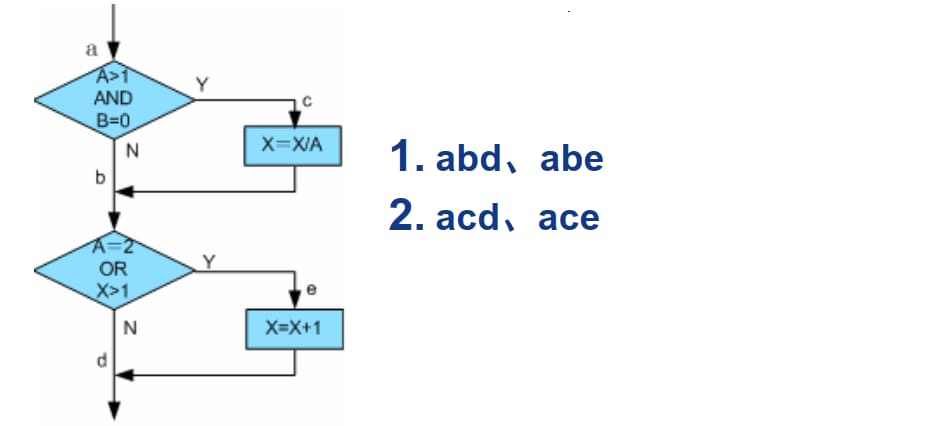
上面四个例子虽然满足条件组合覆盖,但并不能覆盖程序中的每一条路径,例如路径 acd 就没有执行,因此,多条件覆盖标准仍然是不彻底。
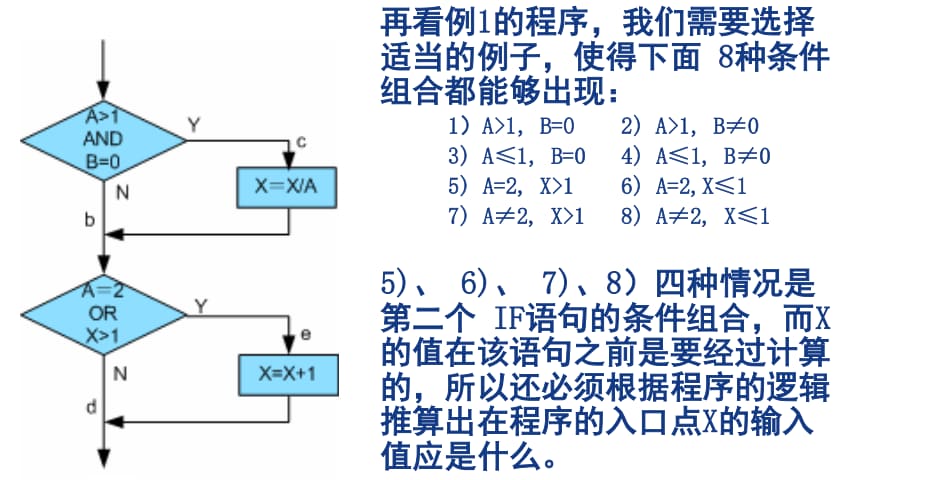
4.1.3.5. 分支 / 条件覆盖
执行足够的测试用例,使得分支中每个条件取到各种可能的值,并使每个分支取到各种可能的结果。
4.1.3.6. 路径测试(C∞)
路径测试就是设计足够多的测试用例,覆盖被测试对象中的所有可能路径。
4.1.3.7. 循环测试
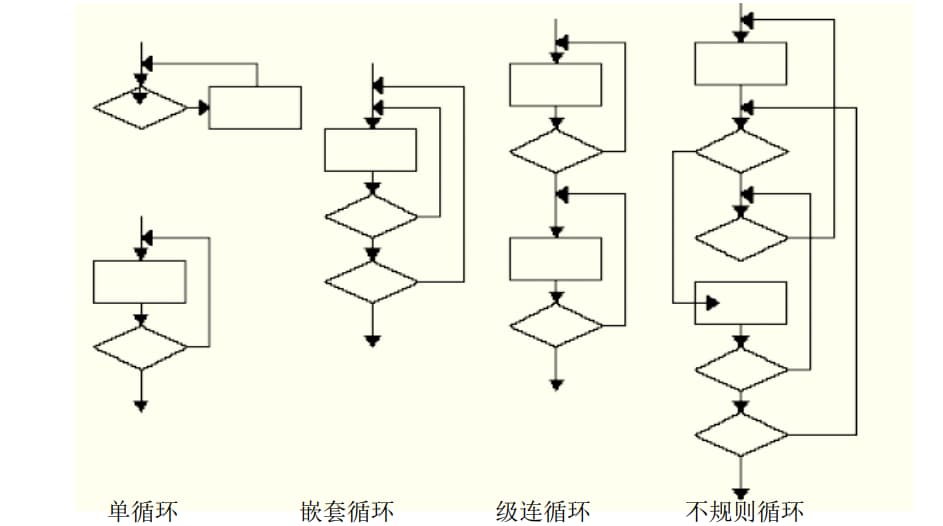
- 单循环测试:
- 假设循环次数为N
- 直接跳过循环
- 循环次数为1
- 循环次数为2
- 循环次数为M,M < N
- 循环次数为N – 1,N,N + 1、
- 假设循环次数为N
- 嵌套循环测试:
- 先测试最内部循环,其它循环次数为1
- 测试第二层循环,其它循环次数为1
- 直到最外部循环完成测试
- 级连循环测试:
- 分别采用单循环测试方法进行测试
- 不规则循环测试:
- 无法测试——重新设计
4.1.4. McCabe 圈数
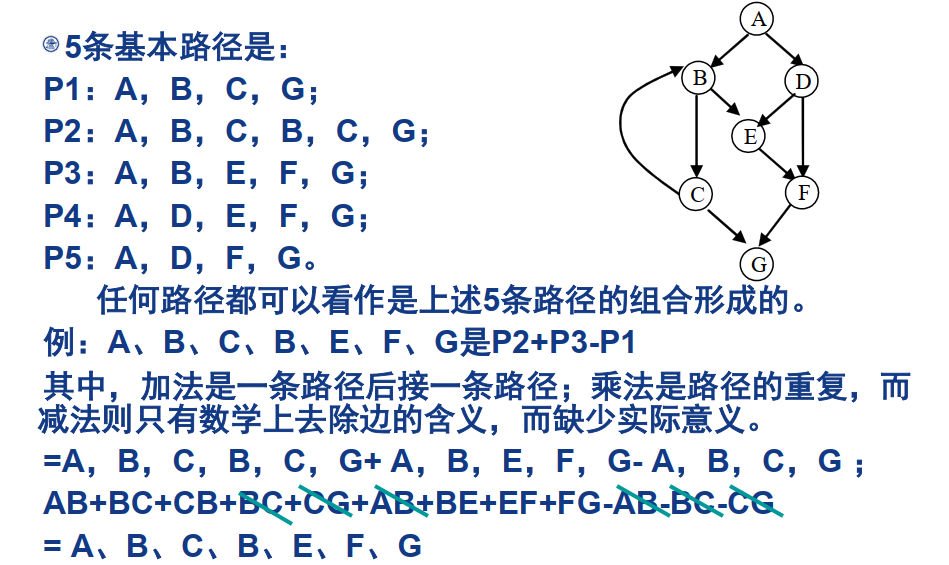
基(本)路径:程序图中相互独立的一组路径,使得该程序中的所有路径都可以用基路径表示。
圈复杂度:是一种为程序逻辑复杂性提供定量测度的软件度量,将该度量用于计算程序的基本的基本路径数目。
基本路径必须从起始点到终止点的路径:
- 包含一条其他基本路径不曾用到的边,或至少引入一个新处理语句或者新判断的程序通路。
- 对于循环而言,基本路径应包含不执行循环和执行一次循环的路径。
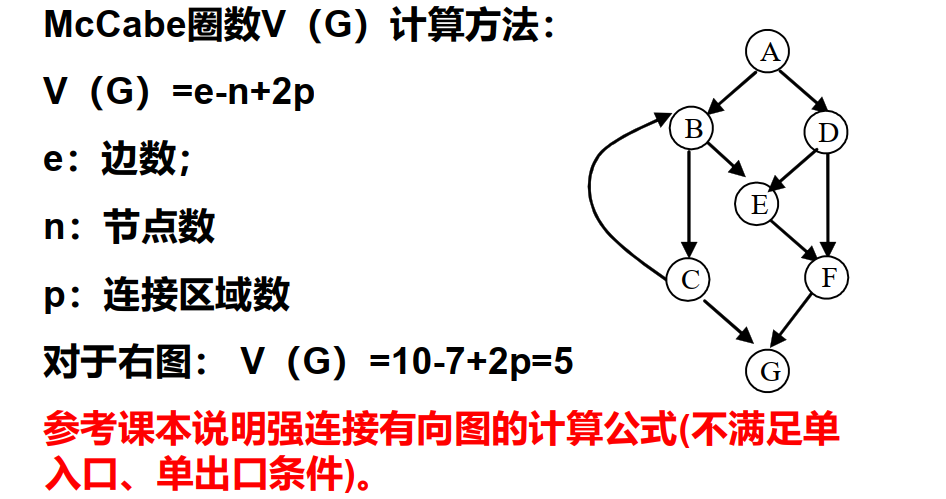
p:流程图中断开部分的数量(调用程序和子程序)
如果是强连接有向图(存在一条从终点指向起点的路径,即整个程序是一个强连通分量),则V (G) = e – n + p 。
圈复杂度另一种计算方式:判定节点的数量 + 1 。
- 判定节点:if; while; for; case; catch; and, or; 三元运算符
1(while) + 1(while) + 1(if) + 1 = 4
void sort(int *A)
{
int i = 0;
int n = 5;
int j = 0;
while (i < (n - 1))
{
j = i + 1;
while (j < n)
{
if (A[i] < A[j])
{
swap(A[i], A[j]);
}
}
i = i + 1;
}
}1(for) + 2(if) + 1 = 4
int find (int match)
{
for (int var in list)
{
if (var == match && var != NAN)
{
return var;
}
}
}一般的,一个单元模块的最大复杂度V (G) < 10。
4.1.5 基于路径的测试讨论
- 可行路径:要求在逻辑上路径可能被执行(如一条路径上不能同时出现 a = 1 与 a > 2 均为真的两条分支!)
- 拓扑路径:遍历路径图,包括所有路径组合,无论逻辑上是否可能

4.2. 数据流测试
核心目的是测试程序的数据流(数据的定义和使用)。
4.2.1. 定义-使用(def-use)测试(基于变量层次)
- 对于程序 P,有程序图 G(P),V 是程序中变量的集合,节点表示语句片,边表示节点序列。
- 节点 n ∈ G(P)是变量 v ∈ V 的定义节点,记做 DEF(v,n),当且仅当变量 v 的值有对应节点 n 的语句片处定义:
- 输入语句、赋值语句、循环控制语句和过程调用语句(定义或更改变量的值),即:向内存地址写入值的语句。
- 节点 n ∈ G(p)是变量 v ∈ V 的使用节点,记做 USE(v,n),当且仅当变量 v 的值在对应节点 n 的语句片处使用:
- 输出语句、赋值语句、条件语句、循环控制语句和过程调用语句,都是可能的使用语句(不改变变量的值)即:从内存地址读取值的语句。
- 使用节点 USE(v,n)是一个谓词使用(记做 P-use),当且仅当语句n 是谓词语句(出现在 条件判断语句(如
if、while、for等),直接影响程序的 执行路径(真/假分支));否则, USE(v,n)是计算使用(出现在赋值、表达式、返回值等非控制语句中,不改变程序流程,仅用于数据计算)(记做 C-use)。
- 关于变量 v 的定义-使用路径(记做 du-path),是PATHS(P)中的路径,使得对某个 v ∈ V,存在定义节点 DEF(v, m)和使用节点 USE(v, n),使得 m 和 n 是该路径的起始和终止节点。
- 关于变量 v 的定义-清除路径(记做 dc-path),是具有起始和终止节点 DEF(v,m)和 USE(v, n)的PATHS(P)中的路径,使得该路径中没有其它节点是 v 的定义节点。
定义-使用路径测试覆盖指标:
- 全定义准则:每个定义节点到一个使用的定义清除路径。
- 全使用准则:每个定义节点到所有使用节点以及后续节点的定义清除路径。
- 全谓词使用/部分计算使用准则:每个定义节点到所有谓词使用的定义清除路径,若无谓词使用, 至少有一个计算使用的定义清除路径。
- 全计算使用/部分谓词使用准则:每个定义节点到所有计算使用的定义清除路径,若无计算使用, 至少有一个谓词使用的定义清除路径。
- 全定义-使用路径准则:每个定义节点到所有使用节点以及后续节点的定义清除路径。包括有一次环路和或无环路的路径。
4.2.2. 基于程序片的测试
- 定义:给定一个程序 P 和 P 中的一个变量集合 V,变量集合 V在语句 n 上的一个片,记做S(V, n),是 P 中对 V 中的变量值作出贡献的所有语句(编号)的集合。
- DEF(定义)的形式有:输入定义、赋值定义。
- USE(使用)的形式有:谓词使用、计算使用、输出使用、定位使用、迭代使用。
- 不同变量程序片的补集,为变量的分段划分提供了方法。
4.2.3. 示例 佣金问题:
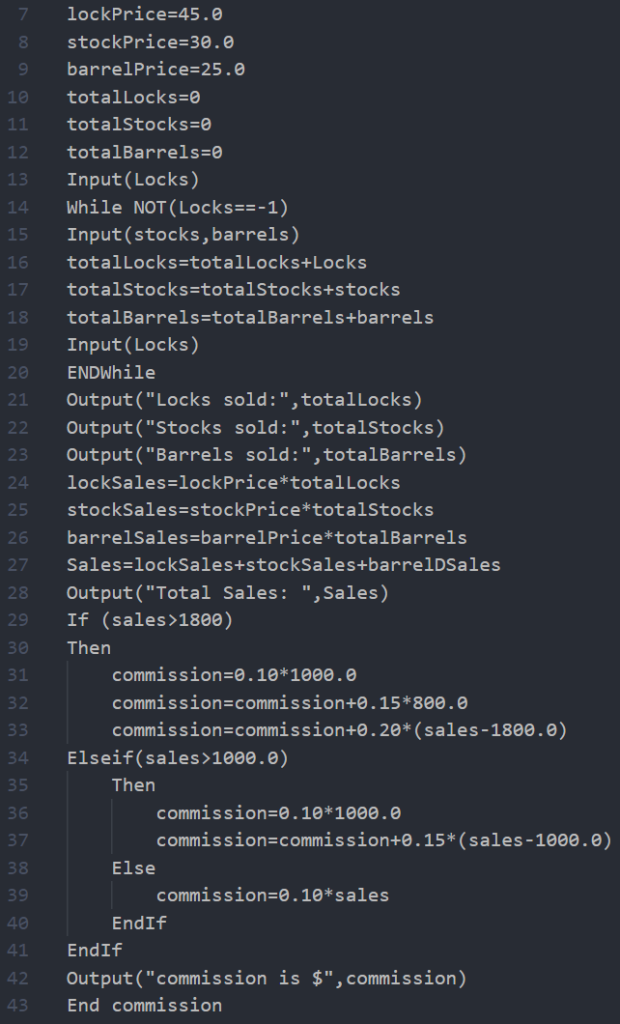
| 变量名 | 定义节点 | 使用节点 |
| lockPrice | 7 | 24 |
| stockPrice | 8 | 25 |
| barrelPrice | 9 | 26 |
| totalLocks | 10,16 | 16,21,24 |
| totalStock | 11,17 | 17,22,25 |
| totalBarrels | 12,18 | 18,23,26 |
| locks | 13,19 | 14,16 |
| stocks | 15 | 17 |
| barrels | 15 | 18 |
| locksales | 24 | 27 |
| stocksales | 25 | 27 |
| barrelsales | 26 | 27 |
| sales | 27 | 28,29,33,34,37,39 |
| commission | 31,32,33,36,37,39 | 32,33,37,42 |
定义使用路径:
- 变量 stocks:有 DEF(stocks, 15) 和 USE(stocks, 17),路径 <15,17> 是一个 stocks 的定义-使用路径,是定义清除路径。
- 变量 locks:有 DEF(locks, 13)、 DEF(locks, 19),USE(locks, 14)、USE(locks, 16)。产生的路径:
- p1 = <13,14>
- p2 = <13,14,15,16>
- p3 = <19,20,14>
- p4 = <19,20,14,15,16>
- 变量 totalLocks:有2个定义节点,DEF(totalLocks, 10)和 DEF(totalLocks, 16);3个使用节点,USE(totalLocks, 16)、USE(totalLocks, 21) 和 USE(totalLocks, 24)。产生的路径:
- p1 = <10,11,12,13,14,15,16> 是定义清除的。
- p2 = <10,11,12,13,14,15,16,17,18,19,20,14,21> 因为节点16是可循环的,存在totalLocks再定义现象,不是定义清除的。
- p3 = <10,11,12,13,14,15,16,17,18,19,20,14,21,22,23,24> = <p2,22,23,24>,当然不是定义清除的。
- p4 = <16,16> 不作为定义-使用路径。
- p5 = <16,17,18,19,20,14,21>。
- p6 = <16,17,18,19,20,14,21,22,23,24>。
基于程序片:
- 变量 Locks 有2个使用节点14、 16, 2个定义节点13、19,则:
- S1:S(Locks, 13)= {13}
- S2:S(Locks, 14)= {13,14,19,20} 14?(因为循环体里有节点19有贡献,所以循环判断有贡献)
- S3:S(Locks, 16)= {13,14,19,20} 16?
- S4:S(Locks, 19)= {13,14,19,20}
- 变量 stocks 和 barrels 要受循环变量locks的影响,所以
- S5:S(Stocks, 15)= {13,14,15,19,20}
- S6:S(Stocks, 17)= {13,14,15,19,20},17?
- S7:S(Barrels, 15)= {13,14,15,19,20}
- S8:S(Barrels, 18)= {13,14,15,19,20},18?
- 变量 totalLocks,节点10是赋值定义,节点16既是赋值又是计算,且存在循环;而节点21和24分别是输出和计算节点,则:
- S9:S(totalLocks, 10)= {10}
- S10:S(totalLocks, 16)= {10,13,14,16,19,20}
- S11:S(totalLocks, 21)= S(totalLocks, 24)= S10
- sales 变量只有1个定义节点27,有28、 29、 33、34、 37、 38共6个使用节点,但影响其值的变量是除 commission 以外的所有变量。所以,sales 变量在所有相关语句上的程序片都一样: S24-30:= {7,8,9,10,11,12,13,14,15,16,17,18,19,20,24,25,26,27}
- 变量commission有6个定义节点, 4个使用节点。所以
- S31: S(commission, 31)={7-20, 24-31}
- S32: S(commission, 32)={7-20, 24-32}
- S33:包含所有变量的影响, S(commission, 33) ={7~20, 24-33}
- S34: S(commission, 36)={7-20, 24-36}
- S35: S(commission, 37)={7-20, 24-37}
- S36: S(commission, 39)={7-20, 24-39}
- S37: S(commission, 42)={7-20, 24-39}
4.3. 测试的效率
什么时候测试可以停止?多少是足够的测试?
- 当时间用完时——缺少标准。
- 当继续测试没有产生新失效时(基于经验的有效方法)。
- 当继续测试没有发现新缺陷时(基于经验的有效方法)。
- 当无法考虑新测试用例时。
- 当回报很小时—基于分析的方法。
- 当达到所要求的覆盖时—结构化测试的指标。
- 当所有缺陷都已经清除时—难以实现。
4.3.1. 漏洞与冗余
4.3.2. 用于方法评估的指标
- 假设功能性测试技术 M 生成 m 个测试用例,并且根据标识被测单元中的 s 个元素的结构性测试指标 S 来跟踪这些测试用例。当执行 m 个测试用例时,会经过 n 个结构性测试单元。
- 定义:方法 M 关于指标 S 的覆盖是 n 与 s 的比值,记做 C(M,S)。
- 定义:方法 M 关于指标 S 的冗余是 m 与 s 的比值,记做 R(M,S)。
- 定义:方法 M 关于指标 S 的净冗余是 m 与 n 的比值,记做 NR(M,S)。
5. 回归测试(Regression Testing)
5.1. 概念
- 定义:在软件修改后,重新执行已有测试用例,确保:
- 修改正确 → 新功能/修复符合预期目的;
- 无副作用 → 未破坏原有功能(避免回归缺陷)。
- 关键措施:
- 重新测试现有功能(验证兼容性);
- 补充测试新/修改部分(覆盖变更点)。
- 概念用词:
- 测试用例库: 存储项目在测试过程中所开发的测试用例,由测试组维护和管理 。
- 基线测试用例库 :针对软件的基线版本(稳定版本)的所有测试用例集合。
- 测试用例库的维护(软件演变会导致用例是去针对性和有效性,需要维护确保有效性):
- 删除过时的测试用例;
- 改进不受控制的测试用例;
- 删除冗余的测试用例;
- 增添新的测试用例。
5.2. 策略总结
- 全量测试(TEST-ALL)
- 做法:执行旧版本所有有效测试 + 新增功能的测试。
- 确保修改后的版本(P’)完全兼容旧功能(P),覆盖全面。
- 资源消耗大,效率低。
- 测试选择(Test Selection)
- 核心目标:从原测试集(T)中选出最小有效子集(Tr),确保:
- 修改后的代码(P’)通过 Tr 即表明旧功能未被破坏。
- 排除过时测试(因代码变更而失效的用例)。
- 节省资源,快速反馈。
- 核心目标:从原测试集(T)中选出最小有效子集(Tr),确保:
选择回归测试策略应该兼顾效率和有效性两个⽅面。常用的选择回归测试的⽅式包括:
- 再测试全部用例:执行所有历史用例 + 新增测试,漏测风险最低,成本高。
- 基于风险选择测试:优先执行高风险(核心/可疑)用例,逐步降低风险值,直⾄满⾜回归测试要求。
- 基于操作剖面选择测试:基于软件操作剖面开发测试用例,优先选择针对最重要/频繁使用的功能的测试用例。
- 再测试修改的部分:通过等价性分析,识别软件的修改情况及影响,局限测试被改变的模块及其接⼝。
5.3. 步骤
回归测试可遵循下述基本过程进⾏:
- 识别软件中被修改的部分;
- 基于原测试用例库 T,排除不再适用的测试用例,确定依然有效的测试用例,构建一个新的测试用例库 T0;
- 依照一定的策略,从 T0 中选择测试用例测试被修改的软件;
- 如有必要,生成新的用例库 T1,用于测试 T0 无法测试到的软件部分;
- 依照一定的策略,从 T1 中选择测试用例测试被修改的软件。
第(2)和第(3)步测试,验证修改是否破坏了现有的功能,第(4)和第(5)步测试验证修改工作本身。
5.4. 代价
- Costx = Analysis + Selective Retest
- Costy = Retest All
- 目标是实现 Costx < Costy
5.5. 回归测试用例选择方法
5.5.1. 基于执行轨迹(路径)与执行切片的选择(Test selection using execution trace and execution slice)
- 给定程序 P 和测试集 T,获取 P 在 T 中每个测试用例的执行轨迹。
- 从执行轨迹中为 P 的 CFG(控制流图)中的每个节点提取测试向量。
- 为 P 和 P’ 的 CFG 中的每个节点构造语法树(syntax trees)。
- 遍历两个 CFG,确定适合用于 P’ 回归测试的测试集 T 的子集。
G=(N,E) 是程序 P 的 CFG,N 是节点的有限集合,E 是连接节点的有限边集,Start 和 End 为特殊节点。定义 Tno为 P′ 的所有有效测试集(移除失效的测试用例,仅包含有效的测试用例)。
Program

CFG
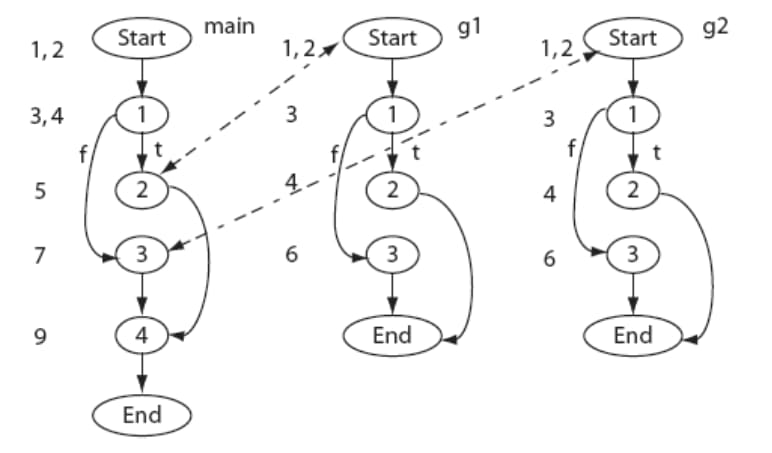
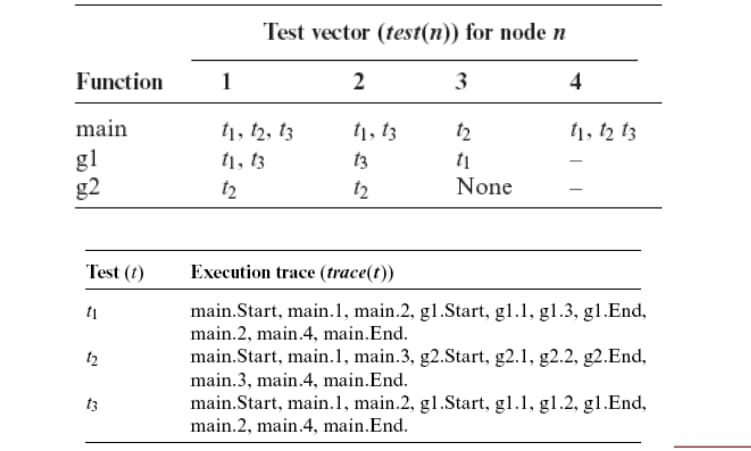
测试用例:t1:< x = 1, y = 3>;t2:< x = 2, y = 1>;t3:< x = 3, y = 4>
测试向量
语法树
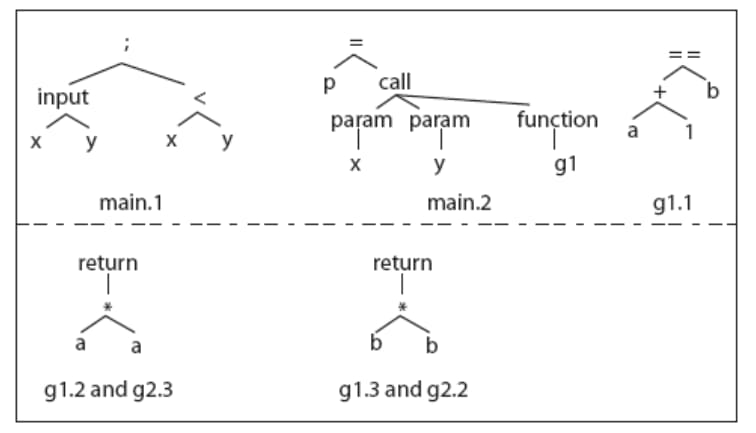
只测试修改过的地方对应的测试用例,如 g1 的节点 1 被修改,则应该测试 T′={t1, t3}。
从 Start 节点开始,使用递归下降的方式并行遍历 P 和 P′ 的 CFG,比较对应节点。如果发现语法不同的节点,将其相关的测试用例加入 T′。

5.5.2. 基于测试最小化的选择(Test selection using test minimization)
通过减少测试集的规模来确保覆盖程序中关键的测试实体。
- 确定用于最小化的测试实体类型,例如函数、语句、决策点、变量定义-使用链(def-use chains)等。
- 对测试集 T 中的所有测试用例运行程序 P,记录每个测试用例覆盖的测试实体。
- 找到最小测试子集 T′,确保每个测试实体至少被 T′ 中的一个测试用例覆盖。
示例1:
- 程序 P 包含两个函数:main 和 f。t1: main;t2: main,f。P′ 是通过修改 f 从 P 中生成的新程序。
- 选择测试用例:因为修改只影响 f,所以 t1 不需要包含在回归测试集中,回归测试集仅包含 t2。
- 使用函数覆盖率,将测试集 {t1,t2} 最小化为回归测试集 {t2}。
示例 2:
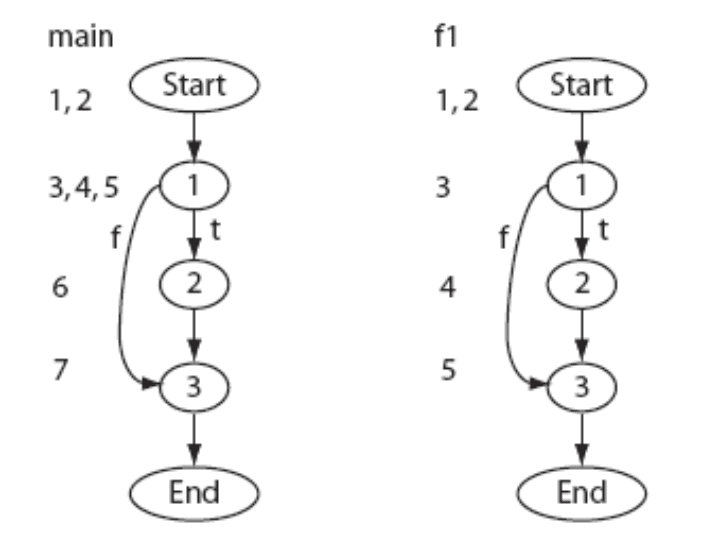
- 测试实体:选择基本块(basic blocks)作为测试实体。
- 测试用例覆盖:
- t1: main: 1, 2, 3,f1: 1, 3
- t2: main: 1, 3,f1: 1, 3
- t3: main: 1, 3,f1: 1, 2, 3
- 最小化测试集:
- 最小测试集为 {t1, t3}。
5.5.3. 基于测试优先级的选择(Test selection using test prioritization)
测试优先级方法通过为测试用例设定优先级,决定执行顺序。
- 选择测试实体:确定感兴趣的测试实体类型(如函数、语句等)。
- 计算覆盖范围:运行测试集 T 中的所有测试,统计每个测试覆盖的测试实体数量。
- 排序测试用例:按照覆盖范围从高到低排列测试用例,赋予优先级。
6. 变异测试(Mutation Testing)
6.1. 概念
- 目的:不同于覆盖率,从另一个角度说明测试的充分性,使测试的充分性加强。
- 定义:程序变异是通过对原程序 P 引入小的修改生成变异程序 P′(mutant),然后测试其行为与 P 的差异性,以评估测试集 T 的质量。
- 逻辑:
- 如果存在测试用例 t ∈ T,使得 P(t) ≠ P′(t),则称 t 杀死了 P′,反之存活。
- 如果 P′ 的行为完全等价于 P,则 P′ 是等价的。
- 评估:
- 测试集不足:如果 P′ 不等价于 P,但测试集 T 无法区分,则 T 被认为是不足的。
- 增强测试集:非等价但存活的变异体提示需要添加新的测试用例。
6.2. 测试充分性评估(Test Adequacy using Mutation)
- 目标:评估测试集 T 是否足够检测程序 P 的缺陷。
- 流程:
- 生成变异体集合 M,包含 k 个变异体 {M1, M2, …, Mk}。
- 检查测试集 T 是否能区分每个变异体 Mi 与原程序 P。如果存在 t ∈ T 使得 Mi(t) ≠ P(t),则称 Mi被杀死(killed)。
- 记录结果:
- 如果所有 k 个变异体都被杀死(k − k1 = 0),则测试集 T 是充分的。
- 如果存在存活变异体(k − k1 > 0),则计算变异得分(Mutation Score, MS): MS = k1 / (k − e) 其中,e 是等价变异体的数量。
6.3. 测试增强(Test Enhancement using Mutation)
- 目标:改进测试集 T,使其更充分。
- 核心:测试的充分性与设计的变异体强相关。
- 流程:
- 检查变异得分 MS。
- 如果 MS = 1,说明当前测试对于这个变异体集合是充分的。
- 如果 MS < 1,说明当前测试对于这个变异体集合是不充分的,存在存活的非等价变异体,需要为其设计新测试用例。
- 为某个存活变异体 m 设计一个新的测试用例 t 。
- 添加 t 到测试集 T,重新计算变异得分 MS。
- 重复上述过程,直至 MS 满足要求。
- 检查变异得分 MS。
6.4. 示例
- 源程序需求应返回两数之和 int foo(int x, y){return (x – y);} <- 显然这里错误,应该 return (x + y)。
- 现在有两个通过的测试 T={ t1:<x = 1, y = 0>, t2:<x = -1, y = 0>}。
- 生成三个变异体:M1:return (x + y); M2:return (x – 0); M1:return (0 – y)。
| Test (t) | foo(t) | M1(t) | M2(t) | M3(t) |
| t1 | 1 | 1 | 1 | 0 |
| t2 | -1 | -1 | -1 | 0 |
| Live | Live | Killed |
- 有两存活 M1,M2;关注 M1 区分 M1 需要满足(x – y≠x + y implies y ≠ 0)的条件,故设计用例 t3:<x = 1, y = 1>。
- 测试 t3 后,能区分 M1,且能发现 t3 也能测试出原函数的错误(M(t) ≠P(t) and P(t) ≠ R(t),R(t)是正确实现)。
6.5. 区分变异体的三个条件
- 可达性(Reachability)
- 测试用例 t 必须覆盖变异体中被修改的语句 s。
- 如果 t 未执行 m 中的 s,则 t 在 P 和 m 上的执行结果必然相同,无法检测到变异体。
- 传染性(Infection)
- 测试用例 t 在执行完 P 和 m 中的语句 s 后,必须使程序状态产生差异。
- 如果程序状态一致,变异体 m 和父程序 P 的行为将无法区分。
- 传播性(Propagation)
- 程序状态的不一致必须传播到程序的输出,导致 P 和 m 的输出不一致。
- 如果不一致未传播到输出,则 t 仍然无法有效区分 m。
6.6. 变异操作符(Mutant Operators)
| 变异操作符 | In P | In mutant |
| 变量替换 | z=x*y+1; | x=x*y+1; z=x*x+1; |
| 关系运算符替换 | if (x<y) | if(x>y) if(x<=y) |
| Off-by-1 错误 | z=x*y+1; | z=x*(y+1)+1; z=(x+1)*y+1; |
| 替换为 0 | z=x*y+1; | z=0*y+1; z=0; |
| 算术运算符替换 | z=x*y+1; | z=x*y-1; z=x+y-1; |
- 一阶变异体:通过一个变异操作生成。
- 高阶变异体:通过多个变异操作生成。
- 设计原则:一般使用一阶变异体模拟程序员常见的简单错误。
- 熟练程序员假设(Competent Programmer Hypothesis,CPH):程序员通常写出的程序仅包含少量错误。
- 耦合效应(Coupling Effect):测试数据可以区分包含简单错误的程序,同时可能隐含区分更复杂的错误,简单的测试用例可以对复杂故障具有高灵敏性。